Nearly all the info online is wrong. May 16 14:14:36 xxxxx sSMTP[807358]: Unable to set TLS_CA_FILE=”/etc/ssl/certs/ca-certificates.crt” If you are relaying to a mail server on port 587, then your ssmtp.conf file should NOT have the line UseTLS=YES. It should have UseSTARTTLS=YES. If you are sending to port 465, then you would want the UseTLS=YES line.
During the COVID-19 pandemic, people have come up with some creative ways to protect one another from the tiny airborne particles (droplets) that come from our mouths and noses. There are some which are funny, some political, others just making a statement. There are a lot of materials one can use to make their own
I was trying to get a printer set up on a Chromebook and after looking through its list for the right model, it wasn’t there. It suggested I give it a PPD file. After some searching, I learned that you can find some compressed PPD files if you download the right Postscript Windows driver from
I wanted to find out the most memory a process used while running. ps_mem.py is great for showing the total size (resident + shared) for processes but it’s only an instantaneous snapshot. After some searching, I found out that a tool I’d known about forever already has (mostly) the feature I wanted: /usr/bin/time.
Sometimes I’m not so great at managing my time. So it makes sense that I’m sometimes not great at managing anyone else’s time either. When it comes to screen time for kids, there needs to be a limit set for how much they use it. We have an Amazon Fire tablet, and it comes with
If you have any interest whatsoever in government spying / intelligence agencies / counter-intelligence, you should read Schneier’s post and its linked story. Everybody has a button. When Equifax was breached, I assumed it was by a group that just wanted to steal identities for profit. Now that it seems it may have been a
I created the following script which saves a few seconds of switching to a terminal and typing grunt on each change to my source files. [crayon-64cebbd7c79b9691409158/] I can just leave this running in a terminal window and glance at the output to make sure there were no errors.
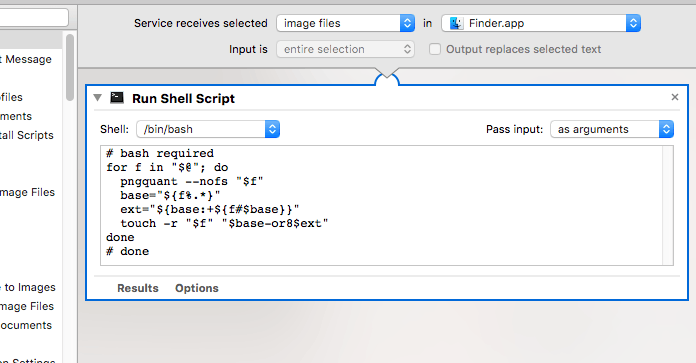
When I save a screenshot on my systems, it doesn’t try to automatically crush/minify the PNG. Here’s how on a Mac I’ve added a context menu item for images to crush them. This can help save storage space or make web pages load faster. Ensure you have pngquant installed. Other tools may work for you,
My current preferred open source, self-hosted & simple RSS reader is Selfoss. I compared several of these types of RSS readers in a prior post and came to different conclusion, but I’ve been using Selfoss for at least a year now. My having switched to it may have coincided with improvements from the mobile reading
I can think of some reasons why folks might use the Googlebot user agent on their non-Google bots, but I can’t think of any good, upstanding reasons to do it. Here’s how one might find some fine folks who would do such a thing. As of right now (May 2018), all valid Google Bot source
[crayon-64cebbd7c894b861302101/] Does this look familiar? Maybe you need more fiber in your diet. Or maybe you need THIS: [crayon-64cebbd7c8958548103311/] You’re welcome.
Logwatch is a great utility for emailing me a summary of system logs over the last 24 hours. One of the things it shows are unsuccessful login attempts and their source IP addresses. But the default unsorted output is hard to analyze and take action on, since a single IP may appear many times in
MemcacheD Is Your Friend is an object caching plugin for WordPress that offers faster access to cached objects, especially if your database happens to reside on a different host. The problem this time around is that it scopes some of its members as private, and as a result, is incompatible with some plugins. I’ve run